

Tutti siamo abituati ad aprire il nostro browser, digitare l’indirizzo o clickare un link e dopo qualche secondo d’attesa trovarci caricato il sito che volevamo guardare.
Ma cosa succede veramente quando scriviamo quell’indirizzo?
Un processo che può sembrare banale, come aprire una pagina web, coinvolge in verità un grande numero di servizi e componenti tecnologiche diverse. Il browser altro non è che un aggregatore di queste che è in grado di coordinarle e farle interagire insieme per mostrare il risultato finale: La pagina desiderata.
Partiamo in ordine…
Risoluzione dell’indirizzo
Digitando l’indirizzo nel grosso campo di testo tipicamente in alto in ogni browser (address bar) si da il via ad un processo chiamato “risoluzione dell’indirizzo” dove il browser cerca di capire a chi deve chiedere il sito web che state cercando di visitare.
Questo processo è solitamente identificato da una scritta “Resolving host…” o equivalente a seconda della lingua del vostro computer al fondo della finestra del browser.
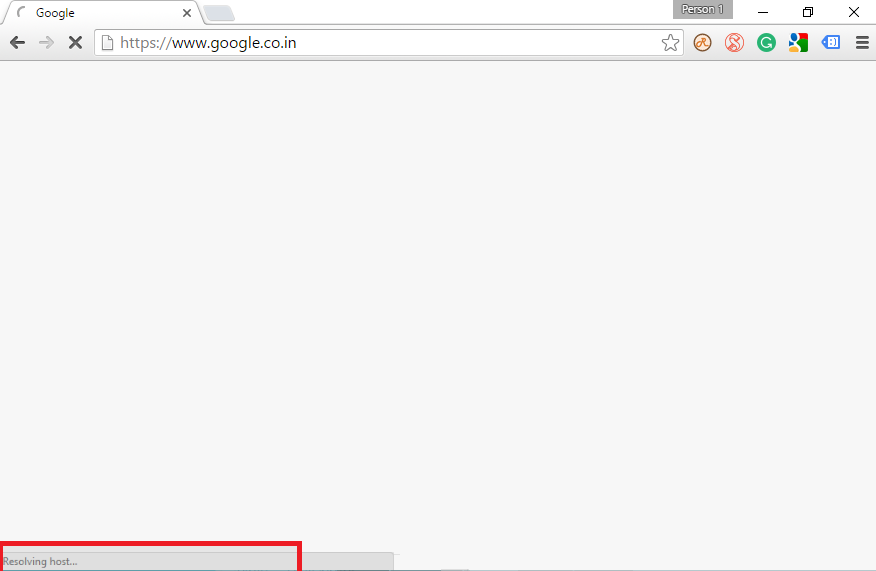
In pratica è come se voi voleste telefonare a qualcuno e sapete solo il suo nome e cognome. Prima di potergli telefonare, avreste bisogno di cercare il suo numero di telefono dentro l’elenco telefonico (Ma l’elenco telefonico esiste ancora? Mi sa che buona parte dei più giovani non ne ha mai visto uno!).
Ecco, il nome del sito www.cnn.it, www.google.com o altro equivale a sapere il nome e cognome della persona. Prima di poter aprire quel sito web il browser deve avere il suo numero di telefono, cioè il suo Indirizzo IP.
La fase di risoluzione dell’indirizzo è proprio quella in cui il browser cerca l’indirizzo IP del sito che state cercando di aprire per poterlo contattare e recuperarne i contenuti. Questa fase è fornita da una tecnologia chiamata DNS (Domain Name System) che è implementata all’interno del browser, come di qualsiasi altra applicazione che lavori su internet, e che gli permette di sapere quale computer contattare su internet.
Connessione HTTP
Una volta trovato il server che deve essere contattato per recuperare il sito web, il browser inizia una comunicazione con esso usando il protocollo HTTP (HyperText Transfer Protocol).
Un protocollo, altro non è che la lingua che due programmi per computer devono usare per comunicare.
Se i due programmi parlano la stessa lingua, si capiscono, e quindi sono in grado di comunicare. Se usano due protocolli diversi invece non si capiscono. Ed è questa la ragione per cui, ad esempio, non possiamo usare un client di posta per guardare un sito web. Il client di posta tipicamente parla i protocolli SMTP, POP e IMAP, mentre un sito web richiede il protocollo HTTP.
Una volta che il browser ha stabilito una connessione col server che detiene il sito web, gli invia un messaggio il cui significato è “Dammi la pagina radice del sito”.
A questo punto, il server, siccome parla HTTP come il browser, capirà il contenuto del messaggio e risponderà con il contenuto della pagina principale del sito. Solitamente chiamata index.html, index.php o qualcosa di simile.
Se si è svolto correttamente, il browser riceverà indietro il contenuto della pagina web ( ad esempio quella della pagina http://www.cnn.it ) e potrà procedere a mostrarlo.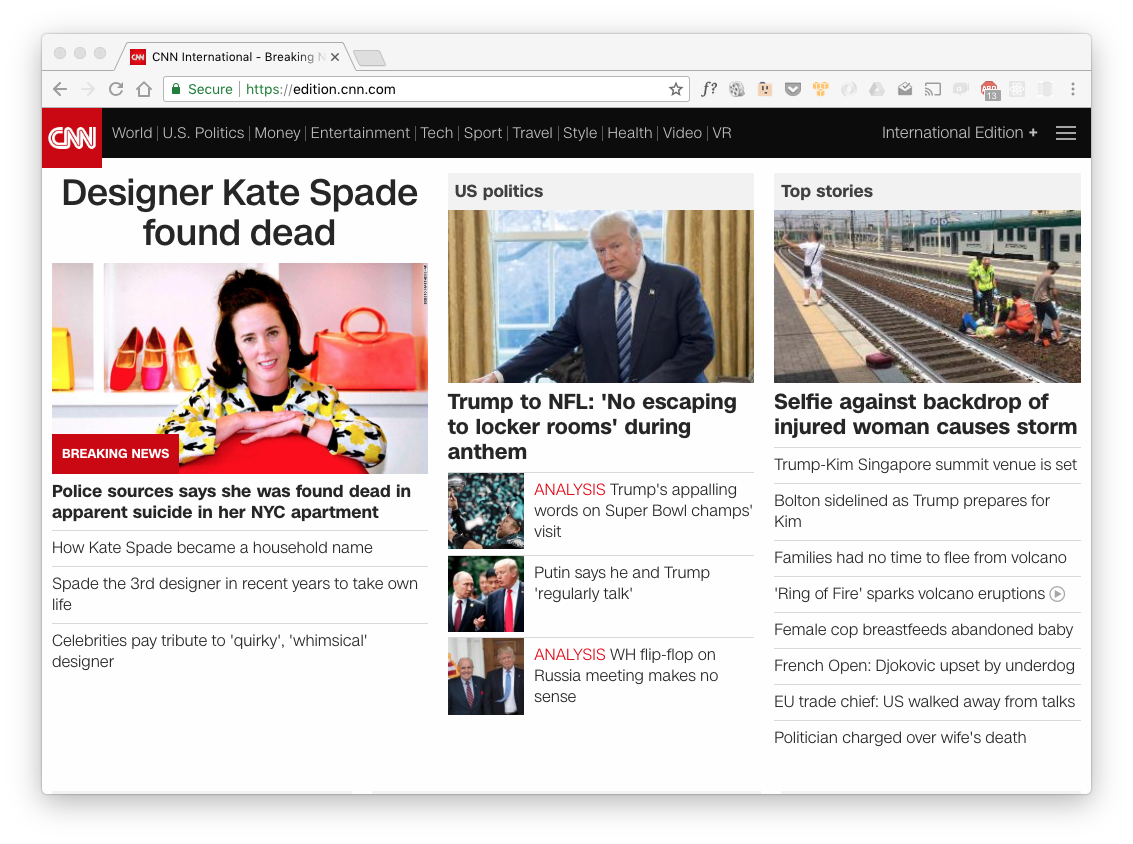
Linguaggio HTML
Al fine di poter mostrare qualcosa, al browser deve essere descritta la pagina web. Gli si deve poter dire “c’è un titolo in alto”, “metti questa immagine lì”, “mostra un menù a sinistra” e così via.
Qui entra in gioco il famigerato HTML ( HyperText Markup Language ), che è il linguaggio (cioè la lingua) che viene usata per descrivere il sito al browser, così che esso sappia cosa deve mostrare e dove.
Se siete curiosi, visualizzare come è stato descritto in HTML un qualsiasi sito web è facilissimo.
I browser consente sempre di visualizzare il “sorgente HTML” (cioè l’HTML che descrive la pagina) di qualsiasi pagina che state guardando. Su Chrome, ad esempio, è sufficiente fare click col tasto destro sulla pagina e si aprirà un menu
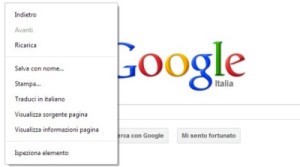
Una delle voci mostrate sarà “Visualizza sorgente pagina” e se la selezionate potrete vedere il sorgente HTML della pagina web che state visualizzando in quel momento
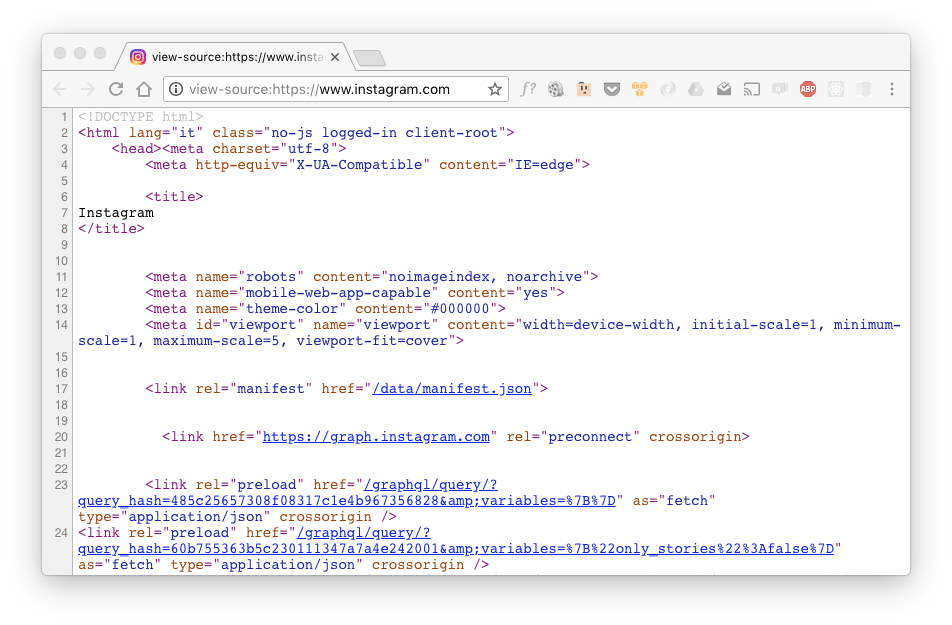
Se non ci capite niente, non preoccupatevi. L’HTML non è pensato per essere letto da umani, è pensato per essere letto dal browser ed in parte dai programmatori che devono scriverlo!
L’importante è capire che l’HTML descrive la struttura della pagina, e dichiara quindi che testo deve esserci (se curiosi in giro per l’HTML della pagina, sicuramente riconoscerai le stesse scritte che puoi leggere nella pagina), che immagini devono esserci, quale è il titolo della pagina ed altre informazioni che possono interessare il browser o i motori di ricerca.


COMMENTI