

Per chiarire in partenza di che tipologia di database stiamo parlando, è bene citare il modello di database relazionale basato su profilo logico-matematico proposto da Edgar Codd nel 1970. Con questo modello relazionale si proponeva la permissione dell’indipendenza dei dati, ovvero l’indipendenza delle applicazioni dalla crescita dei diversi tipi di dati e dalle modifiche del database.
Occorre quindi comprendere anche quelle che sono le tre dipendenze delle applicazioni:
- La dipendenza dall’ordinamento;
- La dipendenza dall’indicizzazione;
- La dipendenza dal percorso di accesso dei dati.
Con il termine relazione si intende ovviamente matematicamente una relazione, ovvero un insieme formato da ennuple, o tuple ordinate, elenchi ordinati di un certo numero di oggetti. La relazione viene quindi rappresentata facilmente come una tabella.
In un database relazionale tutti i dati sono rappresentati come relazioni, e quindi come tabelle/matrici.
Una matrice che rappresenta appunto una relazione, nel modello proposto da Codd, ha le seguenti proprietà:
- Ogni riga è una ennupla;
- Tutte le righe sono differenti;
- L’ordine delle righe non è rilevante ma l’ordine delle colonne sì, perché corrisponde ai domini su cui la relazione è definita, ovvero ai “confini” entro cui sussiste la sua veridicità;
- Il significato di ogni colonna viene trasmesso parzialmente attraverso un’etichetta che coincide con il dominio corrispondente.
Per poter agire sulle matrici vengono utilizzate due tipologie di linguaggi:
- L’algebra relazionale, che esamina le interrogazioni nel database e descrive la procedura da attuare per ottenere il risultato;
- Il calcolo relazionale, che ha invece una funzione dichiarativa, non procedurale. Dunque mostra il risultato ma non come arrivarci. Il calcolo relazionale agisce sia sugli elementi ordinati, ovvero le tuple, che sui domini delle relazioni.
A partire dal calcolo relazionale formulato da Codd è stato implementato il linguaggio SQL, ovvero lo standard per database relazionali.
Le regole di Codd

Nel 1985 Codd definì i requisiti affinché un database potesse dirsi davvero relazionale, le cosiddette “12 regole di Codd”:
0 – La regola zero stabilisce che un sistema possa definirsi un RDBMS se usa solo le funzionalità relazionali per gestire i database;
1 – La numero uno, che le informazioni nel database debbano essere rappresentate sotto-forma di tabella;
2 – La regola due stabilisce che ogni dato debba essere accessibile senza ambiguità, specificando il nome della tabella che lo contiene, il nome della colonna in cui si trova e il valore della chiave primaria;
3 – La regola tre si occupa invece della gestione della rappresentazione di informazioni mancanti o inadatte: un RDBMS deve consentire all’utente di lasciare un campo vuoto o con valore “NULL” e occuparsi della rappresentazione di queste informazioni sempre allo stesso modo;
4 – La regola quattro impone un dizionario di metadati, quindi una descrizione logica di database e oggetti accessibile agli utenti con lo stesso linguaggio di interrogazione usato per accedere ai dati;
5 – Secondo la regola cinque, i dati devono essere accessibili con un linguaggio relazionale che abbia sintassi lineare e che dunque possa essere letto da sinistra a destra, che possa essere usato in forma interattiva o inserito dentro applicazioni, supporti operazioni di definizione e manipolazione dei dati, nonché le regole di sicurezza e i vincoli di integrità del database;
Ogni database ha infatti vincoli intra-relazionali, che riguardano una sola tabella, e inter-relazionali, che riguardano le relazioni tra più tabelle. Questi vincoli sono proprietà che devono essere soddisfatte al momento dell’interrogazione al database: vengono considerate ammissibili solo quelle che soddisfano tutti i vincoli predefiniti e non altrimenti.
6 – La regola sei tratta dell’aggiornamento delle viste, cioè dei “modi di vedere i dati” e specifici subset: se il contenuto di queste viste è modificabile concettualmente, deve esserlo anche praticamente;
7 – La regola sette stabilisce che il database relazionale debba essere manipolato anche per set di dati e non per singole informazioni.
8 – La regola otto riguarda l’indipendenza dalla rappresentazione fisica;
9 – La regola nove è strettamente legata alla regola otto e riguarda l’indipendenza dalla rappresentazione logica.
Le modalità di accesso al database non cambiano anche se vengono modificate le strutture di memorizzazione fisica. Le modifiche al piano logico invece non devono richiedere modifiche ingiustificate alle applicazioni.
Quindi: in un RDBMS la struttura logica è indipendente dalla memorizzazione fisica; la modifica della struttura logica non dovrebbe intaccare le applicazioni del sistema operativo.
10 – La regola dieci ribadisce il concetto di sopra, infatti ci dice che vincoli di integrità vengono memorizzati nel dizionario dei metadati e separati dalle applicazioni;
11 – La regola undici riguarda invece l’indipendenza di localizzazione poiché le applicazioni devono poter continuare a funzionare a prescindere da dove il database sia localizzato fisicamente;
12 – La regola dodici infine stabilisce la non sovversione: gli strumenti per accedere ai dati non possono aggirare i vincoli o le regole di sicurezza.
Per alcuni, un database che non implementi tutte le 13 regole non può dirsi relazionale, per altri questa posizione è particolarmente rigida.
Database relazionale e non
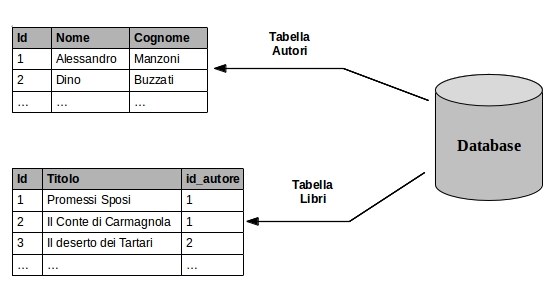
Nei RDBMS, i database relazionali, la strutturazione dei contenuti è molto rigida: i dati vengono normalizzati e inseriti in delle tabelle, quindi salvati secondo un preciso schema. Lo schema definisce righe, colonne, indici, relazioni tra tabelle e ulteriori elementi e attua l’integrità referenziale nelle relazioni. Infine le prestazioni di esso dipendono dal sottosistema di dischi.
Nei DBMS, i database non relazionali, i dati vengono salvati in documenti, archiviati in collezioni, senza tabelle né schemi univoci. I DBMS offrono modelli per chiave-valore, documento e grafo. Per esempio, per tre informazioni relative ad una persona, un RDBMS crea una tabella a tre colonne, un DBMS salva tre dati in formato testuale.
Vantaggi di un Database Relazionale
Per iniziare, è bene dire che il primo vantaggio è quello dell’indipendenza dalla rappresentazione fisica. Difatti la struttura logica di un RDBMS è separata dalle strutture fisiche di memorizzazione. Ciò significa che in questo modo lo storage fisico non compromette l’accesso ai dati. Ad esempio, rinominare un file di database non comporta rinominare tutte le tabelle al suo interno.
A seguire abbiamo l’indipendenza dalla rappresentazione logica, poiché le modifiche al piano logico in un RDBMS non devono richiedere modifiche ingiustificate alle applicazioni e non intaccano il funzionamento delle applicazioni del sistema operativo. Le operazioni logiche consentono all’applicazione di specificare il contenuto richiesto, le operazioni fisiche determinano come accedere ai dati ed eseguono l’attività.
Infine vi è l’indipendenza dalla localizzazione, in quanto le applicazioni continuano a funzionare a prescindere da dove il database sia localizzato fisicamente.
Poiché i vincoli di integrità propri del database relazionale sono un modello di coerenza dei dati tra applicazioni e copie di database, vorrà dire che avremo più istanze del database che contengono sempre gli stessi dati con variazioni in tempo reale. Per questa ragione, i RDBMS sono utilizzati nelle operazioni critiche come le transazioni e-commerce, proprio per proteggerli da inserimenti errati. I vincoli di integrità possono infatti evitare la duplicazione di righe nella stessa tabella, quindi l’inserimento di informazioni errate o ridondanti nel database.
I database relazionali è rigido nell’applicazione di una modifica permanente dunque non la esegue finché non è sicuro di poterla eseguire per tutte le parti che compongono la sezione da modificare.
L’atomicità, ovvero considerare ogni transazione unica, senza esecuzioni parziali, garantisce l’accuratezza nel database e la compliance con le policies aziendali.
Svantaggi
Un RDBMS è strutturato rigidamente, come abbiamo già spiegato nelle righe precedenti. Dunque i dati vengono inseriti secondo schemi precisi che non favoriscono la flessibilità nelle applicazioni. Questo però non permette che tutte le tipologie di dati vengano rappresentate in questo schema. Difatti se un’applicazione secondaria non ha tutti i requisiti, anche di rete, che gli permettano l’inserimento di dati nelle tabelle del sistema, questi dati potrebbero essere semplicemente “saltati” nella lettura, perché non arrivati al tempo necessario.
La normalizzazione dei dati, ovvero la lettura, il trattamento e la suddivisione delle informazioni su tabelle separate, porta ad una loro segmentazione. Questo significa che i dati tra loro correlati potrebbero non finire nella stessa categoria della tabella, ma verrebbero segmentati e ulteriormente suddivisi. Questo può portare a interrogazioni più complesse, su più tabelle, con maggiori tempi di latenza, dunque un movimento più lento da parte del sistema.
La strutturazione dei database relazionali non consente di creare sotto-tuple o classi strutturate gerarchicamente. Ciò lascia intendere quello che abbiamo spiegato di sopra, ovvero che è possibile che i dati tra loro correlati, anche in maniera gerarchica, non vengano collegati tra loro, ma alienati o intesi come una seconda categoria di dati, differente dalla prima.
Altri Modelli di Database
Vi sono altri modelli di database, oltre ai database relazionali. Esistono database gerarchici, reticolari e a oggetti:
- Il modello di database gerarchico prevede un’organizzazione dei dati ad albero. L’albero è formato da una radice, chiamata anche segmento o padre, e da uno o più sottoalberi dipendenti. Le informazioni vengono rappresentate usando le relazioni tra “padri” e “figli”, ovvero uno-a-molti. Per esempio: un padre, molti figli ma non un figlio molti padri. È un sistema molto funzionale per le informazioni gerarchiche, però il modello fatica ad essere applicato in caso di relazioni molti-a-molti dato che in questo caso, è necessario duplicare i dati.
- Il modello di database reticolare si basa su uno schema logico in cui dei quadrati rappresentano i record, ovvero l’insieme di dati compositi, e delle frecce dette puntatori, ovvero tipi di dati che rappresentano la posizione degli elementi. I puntatori uniscono i record e sono creati dal comando chiamato “set”. Tra due record, si può creare solo una relazione uno a molti.
- Il modello di database a oggetti presenta degli elementi del database relazionale. Presenta infatti diversi tipi di basi di dati per oggetti, che possono essere predefiniti, costruiti e definiti dagli utenti.





COMMENTI