

Quando si parla di intelligenza artificiale, ci immaginiamo spesso computer pensanti che svolgono ragionamenti come se fossero esseri umani. Mugugnano tra sé e sé e dopo grandi riflessioni propongono la risposta definitiva alle nostre domande. Un po’ come “Pensiero Profondo“, il supercomputer di Guida Galattica per Autostoppisti progettato per trovare la risposta alla “domanda fondamentale sulla vita, l’universo e tutto quanto”.

In verità siamo ben lontani da questi scenari e quando parliamo di intelligenza artificiale, solitamente, al momento in cui questo articolo è stato scritto, ci riferiamo a due insiemi di tecnologie ben specifiche: L’Apprendimento Automatico (Machine Learning) e le Reti Neurali (Neural Networks).
Entrambi, in un modo o nell’altro, sono figli della statistica e della matematica più pura, ma questo non ci deve spaventare. E` possibile approcciarli entrambi in un modo molto pragmatico e capirne il funzionamento anche senza essere dei matematici esperti. Anzi, la matematica non è per nulla necessaria a capirne il funzionamento generale.
Intelligenza Artificiale: Apprendimento Automatico
Il machine learning è un vastissimo insieme di tecnologie, praticamente racchiude qualsiasi tecnologia che permetta ad un computer di riconoscere ricorrenze e similitudini in un insieme di dati.
Per fare un esempio, potremmo chiedere ad un sistema di machine learning di riconoscere se una canzone ci piace o no sulla base di tutte le canzoni che ci sono piaciute in passato. Questo è un tipo esempio di riconoscimento di similitudini: Se quella canzone ti era piaciuta, allora ti dovrebbe piacere anche questo che ci assomiglia.
In pratica è quello che fanno i vari servizi musicali: Spotify, Google Music, Youtube Music, Amazon Music etc… se gli chiedete di consigliarvi una canzone che potrebbe piacervi.
Andranno a vedere le canzoni che avete ascoltato in passato e cercheranno delle altre canzoni che siano simili a quelle che vi erano piaciute.
Allo stesso modo, possiamo chiedergli di consigliarci dei cibi, dei quadri o di riconoscere se quello nella foto è un gatto o no. Ovviamente i vari sistemi a disposizione avranno un grado di accuratezza diverso, e le tecnologie che sono più adatte a riconoscere le foto dei datti magari sono totalmente inadatte a riconoscere la musica che ci piace. Ma il concetto resta il medesimo.
Similitudini e Distanza
Alla base tra tutto quindi ci sono le similitudini tra i dati che gli forniamo.
Potremmo definire la similitudine tra due oggetti anche come la distanza che c’è tra di loro.
Se due oggetti non sono per niente simili, saranno molto lontani tra di loro. Se invece sono particolarmente simili, saranno molto vicini. Il fatto che parliamo di distanze, significa che possiamo disegnare su una mappa tutti questi oggetti (o i dati che li rappresentano). In quanto la distanza è per definizione lo spazio che intercorre tra due punti.

In qualche modo, quindi A e B sono due canzoni, due quadri o due piatti. E stiamo chiedendo al computer di trovare tutti quelli che sono all’interno di un’area che definisce “la nostra preferenza”.
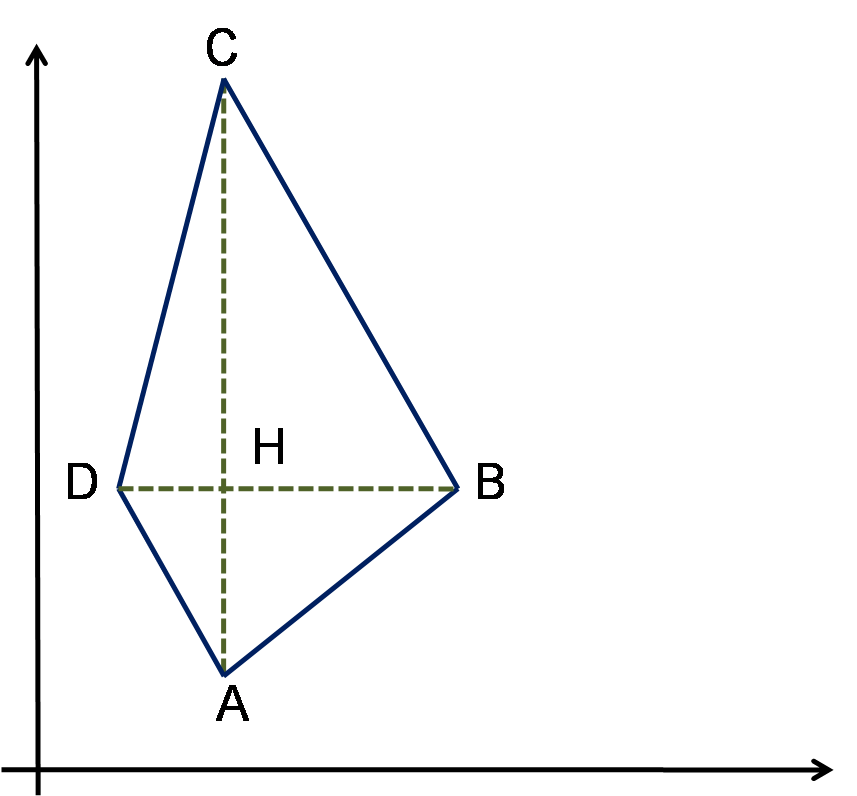
Ad esempio, tutte le canzoni che sono dentro l’area blue delimitata dai punti A,B,C,D saranno le canzoni che ci piacciono. Tutte quelle fuori da quell’area, invece, saranno le canzoni che non ci piacciono.
I dati
Ma come è possibile rappresentare una canzone come un punto? Che valore di X ed Y darò a quella canzone?
Bhe, per noi che siamo esseri umani, calcolare la distanza di solito si limita al concetto di calcolare la distanza in un piano a 2 o 3 dimensioni. Solitamente in 2D è dove ci viene più facile e naturale, ma siamo abituati a ragionare facilmente anche in 3 dimensioni. Per rappresentare un concetto complesso come una canzone, un quadro o un piatto, invece non è possibile ridursi a descriverlo solo come valori di X,Y e Z. Sono necessari decine o centinaia di informazioni. Che cosa descrive una canzone?
Per il computer non è un grosso problema lavorare in più di due dimensioni. Può lavorare in 4, 5, 6 e così via. Se la matematica funziona con due dimensioni, lui può applicarla a qualsiasi numero di dimensioni.
Quindi in verità siamo perfettamente in grado di rappresentare una canzone come qualcosa che ha ben più che solo X,Y,Z, ma che può avere qualsiasi numero di informazioni.
Finché siamo in grado di inserirle nella memoria del computer, siamo in grado di chiedere al computer di calcolare la distanza tra questi due “punti” in uno spazio a N-Dimensioni che rappresentano le nostre canzoni.

Supervisionato e non
Il problema che resta, è: come fa il computer a capire cosa mi piace?
Abbiamo detto che indicativamente, riconosce se una canzone possa piacerci o meno, dal fatto che sia dentro o fuori dall’area che delimita le canzoni che ci piacciono.
Ma come fa a capire quale è l’area delle canzoni che ci piacciono?
Ogni volta che il “machine learning” deve delimitare una o più aree, ci sono due modi in cui può farlo: Quello supervisionato e quello non supervisionato.
Cosa significa? E` molto semplice!
Nel caso del supervisionato, siamo noi stessi ad insegnargli come è fatta questa area.
Ovviamente non gliela descriviamo, perché in verità, nemmeno noi sappiamo esattamente descrivere la rappresentazione di tutte le canzoni che possono piacerci.
Ma gliela descriviamo perché gli diciamo tutte le canzoni che ci sono piaciute e tutte le canzoni che non ci sono piaciute.
A questo punto il computer guarderà a tutte quelle che ci sono piaciute e dirà “Ah! Quindi tutte quelle che sono qua dentro probabilmente ti piacciono!”.

Ad esempio, nell’immagine precedente, le canzoni che ci sono piaciute sono quelle col pallino blue e quelle che non ci sono piaciute, sono quelle arancioni.
Se il computer cerca di dividere in due lo spazio tra quelle che ci sono piaciute e quelle che non ci sono piaciute, probabilmente arriverà a disegnare la linea nera di quell’immagine.
Salvo alcune eccezioni, potrà quindi stabilire che tutte le canzoni al di sotto della linea nera ci piacciono e tutte quelle al di sopra non ci piacciono.
Nel caso dei sistemi non supervisionati, invece, non viene detto niente al computer.
Non gli diciamo nemmeno che ci sono due categorie (le canzoni che ci piacciono e quelle che non ci piacciono). Gli diciamo solamente che vogliamo dividere quelle canzoni.
Sarà il computer in autonomia a decidere quali e quanti gruppi esistono, in base ad alcuni parametri che gli si possono fornire. Ma che cosa rappresentano questi gruppi non lo scopriremo se non dopo che il computer li ha raggruppati.
Quello che il computer andrà a fare, è guardare se ci sono gruppetti di punti che sono vicini tra di loro e lontani da altri gruppetti di punti. Questo significa che tutti quei punti hanno delle caratteristiche simili (in quanto sono tutti vicini tra di loro) e che quindi formano un gruppo.
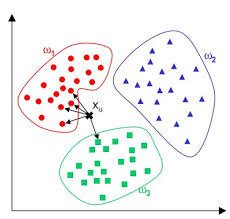
Sarà il computer in autonomia a cercare di creare questi gruppi, sulla base delle informazioni che ha di ogni canzone, senza bisogno che noi gli spieghiamo niente.
Se cerchiamo di spiegare l’intelligenza artificiale con la teoria e la matematica che ci sono dietro, è decisamente complessa da capire anche molti informatici capaci. Ma se cerchiamo di spiegarla con la geometria è facile vedere che praticamente ci rifacciamo alla naturale tendenza che ha anche l’uomo di catalogare ed organizzare tutto in gruppi e per somiglianze.
Il problema è che la descrizione di un gruppo, non è un semplice cerchio. Quindi non basta un punto centrale ed un raggio per descrivere il gruppo che rappresenta tutte le mie canzoni preferite.
Se ci rifacciamo al disegno con i punti blue ed arancioni separati dalla linea nera, è abbastanza evidente che l’equazione che descrive quella linea nera sarà qualcosa di molto difficile (non è una semplice retta o una curva) ed è proprio questa la ragione per cui la matematica coinvolta nell’intelligenza artificiale è così difficile. Perché deve poter rappresentare aree e linee che sono particolarmente complesse, il cui scopo è rappresentare qualcosa di astratto ed articolato come i gusti di una persona.




COMMENTI