
Ogni giorno ti capita di guardare video su un dispositivo elettronico, tablet, smartphone o pc, ma ti sei mai chiesto come funzionano?
Se oggi riusciamo a vedere filmati in alta definizione con grande fluidità sui nostri computer è grande a tecnologie che sono state sviluppate negli ultimi 30 anni e che hanno rivoluzionato il modo di concepire archiviazione digitale dei filmati. Tecnologie che rientrano nei sistemi di compressione video.
Come funziona un video?
In generale un video altro non è che una serie di foto mostrate il più velocemente possibile in rapida successione.
Mostrando le immagini una dopo l’altra nell’ordine di qualche decina al secondo è possibile dare l’effetto di movimento tipico dei filmati.
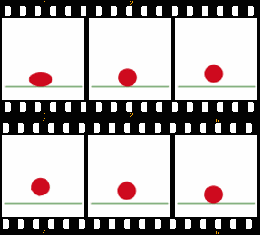
In particolare, il video che siamo abituati a vedere quotidianamente mostra tipicamente 24-25 immagini al secondo. Il numero di immagini al secondo mostrate da un video è chiamato frame rate o anche FPS (frames per second) di cui sicuramente avete sentito parlare in ambito videoludico.
Compressione Video
Se fate un rapido calcolo, è evidente che mostrare 25 immagini al secondo salvandole esattamente come salvereste una fotografia sul vostro computer raggiungerebbe dimensioni che non sono realistiche in termini di spazio occupato.
Facendo un rapido esempio, una fotografia a media risoluzione in JPEG occupa 300Kb. Dovendone mostrare 25 al secondo occuperemmo 7,5MB ogni secondo. Un filmato di 1 ora sarebbe quindi grande 27GB. Considerando che un DVD solitamente può contenere 4,7GB di dati, significherebbe che il film medio andrebbe distribuito su una decina di DVD con tutta la fatica che comporterebbe sostituire il disco ogni dieci minuti di film.
Per fortuna si è riusciti a trovare un modo più furbo per rappresentare questi filmati e solitamente oggi giorno siamo abituati a valutare i consumi di un video in termini di Kbit/s, cioè ottavi di KB per secondo.
Un’ora di video da 300Kbit/s consuma solo 135MB, decisamente meno dei precedenti 27GB ed un valore che consente realisticamente di trasmettere questi video via internet dando così il via alla nascita di sistemi come YouTube, Netflix e concorrenti.
Il processi di riduzione della dimensione di questi video è chiamato “compressione” e solitamente parliamo di compressione lossy cioè di un tipo di compressione dove c’è una leggera perdita di qualità, il più delle volte mirata ad essere invisibile all’occhio umano.
Ovviamente maggiore sarà la compressione, maggiora sarà la perdita di qualità. E se un video poco compresso può avere una qualità molto alta, andando ad aumentare la compressione si ricade facilmente in quell’effetto di “cubettoni” che si muovono per lo schermo.
Come funziona la compressione video?
Il processo di compressione di un video è abbastanza lungo e variegato, molto dipende dal tipo di formato che stiamo usando. MPEG2, H264, WEBM… Ci sono decine di modi in cui si può comprimere un video e tutti daranno risultati più o meno differenti in base alla tipologia di video.
Tuttavia in linea di massima tutti questi formati di compressione video condividono alcuni punti fermi che cercheremo di descrivere di seguito.
Per prima cosa abbiamo detto che il video è costituto da una serie di immagini e che per mostrare il video dobbiamo mostrare tutte queste immagini una dopo l’altra.
Il problema è che salvare tutte queste immagini costa parecchio spazio, quindi per risparmiare spazio i formati video solitamente non salvano tutte le immagini. Ma salvano una sola immagine intera ogni N immagini. Tipicamente si salva una immagine intera ogni 12 immagini. Delle restanti 11 vengono salvati solo i pezzi di immagine che sono cambiati rispetto all’immagine precedente.
In questo modo, invece di dover salvare 12 immagini intere, possiamo salvare la prima per intero e poi solo il pezzo che cambia tra la prima e la seconda, poi solo il pezzo che cambia tra la seconda e la terza e così via.
Le immagini che vengono salvate per intero sono chiamate I-FRAMEs e quelle di cui è salvata solo la differenza rispetto la precedente immagine sono chiamate P-FRAMEs.

Sì, ma le differenze?
Abbiamo detto che i P-FRAMEs, cioè le immagini di cui salviamo solo la parte che è cambiata dal fotogramma precedente, sono create calcolando solo cosa è cambiato dall’immagine prima.
Ma come fa il computer a capire cosa è cambiato dall’immagine prima?
In pratica l’intera immagine viene divisa in delle piccolissime immagini, di dimensione 8×8 pixel.
Ognuna di queste immagini è solitamente rappresentata in un formato come JPEG.
Prese la decine di piccole JPEG 8×8 esse vengono sovrapposte all’immagine precedente, se il contenuto di quell’area dell’immagine non è cambiato allora non c’è bisogno di salvare quella parte di immagine.
Solo i blocchi 8×8 che sono effettivamente cambiati vengono salvati.
Proprio l’uso di questi blocchetti 8×8 è la ragione per cui quando qualcosa non va nel vostro video iniziate a vedere dei quadrati “rotti” in giro per lo schermo. Quei quadrati rotti sono le parti di immagine di cui sono andati persi i quadratini 8×8 probabilmente per problemi di rete o di salvataggio del file su disco o altro.
E` facile vedere come nel caso in cui un venga perso uno dei fotogrammi il video inizierà a mostrare contenuti a caso, perché tutte le successive immagini era calcolate per differenza da quella che è andata persa. Per questa ragione solitamente più di un I-FRAME viene inserito nel video, affinché presto o tardi si incontri di nuovo una immagine intera ed il video riprenda ad aver senso quanto prima.
Avrete notato che a volte, quando si rompe il video lo vedete rotto per un po’ e poi di colpo l’immagine torna perfettamente visibile. Ecco, il momento in cui l’immagine torna perfettamente visibile è perché avete incontrato un I-FRAME e quindi l’intero contenuto del video è stato ridisegnato.
Oggi giorno, che anche la televisione funziona su video digitale (il digitale terrestre) vi sarà sicuramente capitato di incontrare questi fenomeni, in quanto una cattiva ricezione del segnale causa proprio la perdita di alcuni fotogrammi del video coi risultati che abbiamo sopra descritto

Altro?
Come anticipato, ogni formato video è un mondo a sé stante.
Ci sarebbero tante altre cose da dire, ad esempio i vettori di movimento consentono ai video non solo di salvare la differenza tra due immagini, ma anche di non doverla salvare affatto se la differenza è solo di posizione di un pezzetto dell’immagine (questo quadratino qui, che prima era in quella posizione ora si è spostato là).
Oppure che la rappresentazione dell’immagine stessa è studiata per dare priorità alla luce, perché ci si è accorti che l’occhio umano da molta più attenzione alla luce che al colore e che i dettagli delle zone in ombra possono essere facilmente trascurati perché l’occhio tenderà a cadere sulle parti più illuminate.
Il mondo della compressione dei video è ancora un mondo in piena fase di ricerca ed ogni giorno nascono nuovi risultati che migliorano lo stato dell’arte. Sicuramente se ci sarà interesse, ci saranno nuovi articoli sul mondo delle immagini e dei video e ci sarà occasione di affrontare nel dettaglio tutte le particolarità di una scienza così vasta ed interessante come la rappresentazione digitale dei segnali analogici che è alla base di tutto ciò che ci consente di vedere foto, video ed ascoltare musica sul nostro PC!



COMMENTI